Loading...
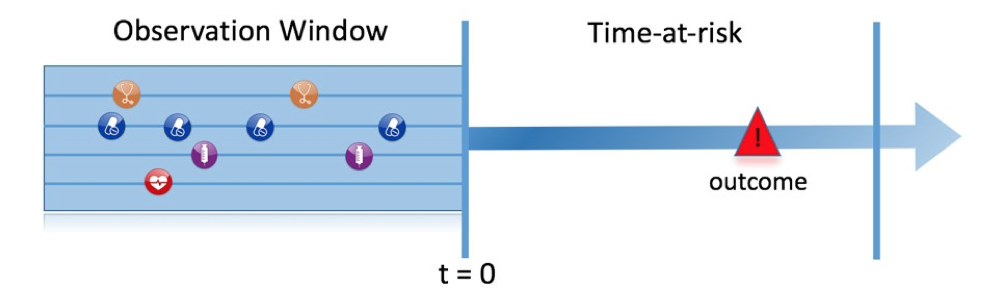
Figure 1.
The variable scatter plot shows the mean covariate value for the people with the outcome against the mean covariate value for the people without the outcome.
The meaning of the size and color of the dots depends on the settings on the left of the figure.
Table 2.
This table shows for each covariate the mean value in persons with and without the outcome and their mean difference.
Loading...